Answer:
The Chi - Square Test Statistics is 13.98
p-value = 0.0002
CONCLUSION: Since the p-value is less than the level of significance ; (i.e p-value < ∝) we reject the null hypothesis and accept the alternative hypothesis.
Thus; there is a difference in the population proportion of glove fitness for the two genders.
Explanation:
From the information given ; the structure of the table can be well represented as follows;
Observed data Males Females Total
Gloves fit poorly 132 20 152
Gloves fit well 415 19 434
Total 547 39 586
Expected data Males Females Total
Gloves fit poorly
Gloves fit well
Total
The objective of this question is to use the chi-square test to determine if there is a difference in the population proportion of glove fitness for the two genders.
We call represent the hypothesis as follows:
The null hypothesis:
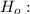 states that there is no difference in the population proportion of glove fitness for the two genders.
states that there is no difference in the population proportion of glove fitness for the two genders.
The alternative hypothesis:
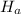 states that there is difference in the population proportion of glove fitness for the two genders.
states that there is difference in the population proportion of glove fitness for the two genders.
The expected frequency of a particular cell can be calculated by multiplying the sum of the rows and columns together, then dividing it by the Total sum
For row 1 column 1 (gloves fit poorly (male) ; we have:
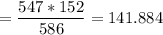
For row 2 column 1 (gloves fit well(male) ; we have:
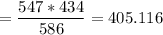
For row 1 column 2 (gloves fit poorly (female)) ; we have:
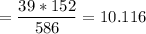
For row 2 column 2 ( gloves fit well ( female ) ; we have:
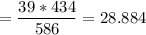
Thus; we can have the complete table to now be:
Observed data Males Females Total
Gloves fit poorly 132 20 152
Gloves fit well 415 19 434
Total 547 39 586
Expected data Males Females Total
Gloves fit poorly 141.884 10.116 152
Gloves fit well 405.116 28.884 434
Total 547 39 586
The Chi - Square Test Statistics can be calculated via the formula:
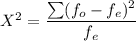
where;
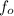 = observed data frequency
= observed data frequency
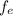 = expected data frequency
= expected data frequency
∴
The Chi - Square Test Statistics is as follows:
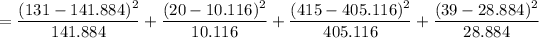
= 0.68+9.6+0.2+3.5
= 13.98
We are given the level of significance ∝ to be = 0.01
numbers of rows = 2; number of column = 2
Thus; the degree of freedom = (2-1)(2-1) = 1×1 = 1
Using the Excel Function : [ = CHISQ.DIST.RT²(X²,df)]
p-value = 0.0002
CONCLUSION: Since the p-value is less than the level of significance ; (i.e p-value < ∝) we reject the null hypothesis and accept the alternative hypothesis.
Thus; there is a difference in the population proportion of glove fitness for the two genders.