Answer:
Explanation:
Hello!
You have the data corresponding to X: the number of pods on a sample of soybean planted in two different plot types ("Liberty" and "No-till")
Liberty Plot 32 31 36 35 44 31 39 37 38
No-Till Plot 35 31 32 30 43 33 37 42 40
a)
The mean of a sample is calculated by dividing the summation of all observations of the sample by its size: X[bar]= ∑X/n
Sample 1 Liberty plot:
X[bar]₁= ∑X₁/n₁=
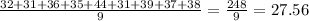
Sample 2 No Till plot:
X[bar]₂= ∑X₂/n₂=
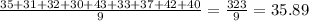
b)
The range of a variable is the interval between the max value and the min value of the variable, it shows you what is the possible dispersion of the values of the variable.
Sample 1:
Max₁: 44
Min₁: 31
R₁: Max₁ - Min₁ = 44 - 31 = 13
Sample 2
Max₂: 30
Min₂: 43
R₂= Max₂ - Min₂= 43 - 30= 13
c)
Sample 1 is centered in X[bar]₁= 27.56 and has a range of dispersion of R₁= 13
Sample 2 is centered in X[bar]₂= 35.59 and it has a range of dispersion of R₂= 13
Considering that the mean of sample 1 is less than the mean of sample 2 you could say that the average yield is greater in the "No-Till" plots.
Both data sets have the same range, this means that the variance of both plots is equal.
It seems that the yield for plots 2 "No-till" is better than the yield for plots 1 "Liberty"
I hope you have a SUPER day!