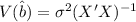Answer:
See explanation below.
Explanation:
If we assume a linear model with two variables and one intercept the model is given by:
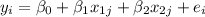
The extension of this to a multiple regression modelwith p predictors is:
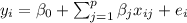
We assume that we have n individuals
![i \in [1,...,n]](https://img.qammunity.org/2021/formulas/mathematics/high-school/wpez2oc5itsrspw5npw4qjyuj2mgbx7842.png)
And the distribution for the errors is
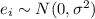
and we can write this model with a design matrix X like this:
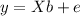
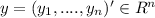 a nx1 response vector
a nx1 response vector
![X = [1_n , x_1,....,x_p] \in R^(nx(p+1))](https://img.qammunity.org/2021/formulas/mathematics/high-school/nddz0gqpe68vjh9v3saoftebvuewe7xryw.png) represent the design matrix nx(p+1)
represent the design matrix nx(p+1)
Where
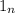 is a nx1 vector of ones, and
is a nx1 vector of ones, and
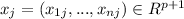 is a (p+1)x1 vector of coeffcients
is a (p+1)x1 vector of coeffcients
And
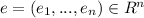 is a nx1 error vector
is a nx1 error vector
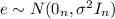
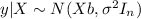
Using ordinary least squares we need to minimize the following quantity:
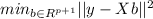
And for this case if we find the best estimator for
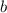 we got:
we got:
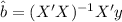
And the fitted values can be written as:
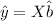
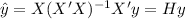
Where
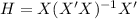
In order to see if any coefficnet is significant we can conduct the following hyppthesis:
Null hypothesis:
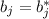
Alternative hypothesis:
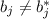
For some j in {0,1,....,p}
We need to use the following statistic:
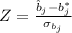
Where
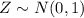
And
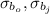 are square roots of the diagonals of the diagomals of
are square roots of the diagonals of the diagomals of