Answer:
C. Predicts someone's blood alcohol level from the number of whiskey drinks they consumed.
Explanation:
In Statistics, classification problems are differentiated from estimation problems because classification problems typically requires that the output attribute be categorical while estimation problems require that the output attribute is numerical. In an estimation problem, the output variable has a continuous or real value, such as predicting the size, area, weight, age or even the cost of an item.
A Classification problem work with the concept of creating a succinct model such as decision trees, Naive Bayes, random forest, logistic regression, etc, which is capable of predicting from the attribute (observed) variables given; values of the dependent attribute, which is always categorical.
In order to predict a dichotomous variable from a given data set comprising of continuous or dichotomous variables, a logistic regression can be used.
Mathematically, it is given by the expression;
Logistic regression
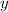 with
with
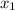 ,
,
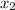 ........
........
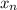
Where;
y represents the dichotomous dependent variable.
,
........
represents the predictable variables, which are categorical in nature such as alive or dead, win or lose, sick or healthy, pass or fail, etc.
Hence, a regression would be appropriate for predicting someone's blood alcohol level from the number of whiskey drinks they consumed.