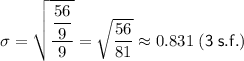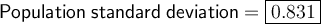Answer:
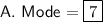

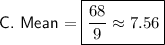
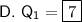
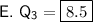
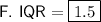
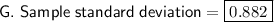

Explanation:
The given data set in ascending order is:
- 7, 7, 7, 7, 7, 7, 8, 9, 9

Mode
The mode of a data set is the value or values that occur most frequently. Therefore, the mode of the given data set is:
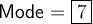
Median
The median of a data set is the middle value when the values are arranged in ascending or descending order. Since the given data set has a total of 9 values, the median is the 5th value:
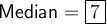
Mean
The mean (average) of a data set is calculated by summing all the values in the data set and then dividing the total by the number of data values. Therefore, the mean of the given data set is:
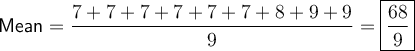
Lower Quartile (Q1)
The lower quartile (Q1) of a data set is the median of the lower half of the dataset. As there are 4 data values to the left of the median, the lower quartile is the average of the middle two data values:
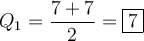
Upper Quartile (Q1)
The upper quartile (Q3) of a data set is the median of the upper half of the dataset. As there are 4 data values to the right of the median, the upper quartile is the average of the middle two data values:
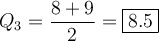
Interquartile Range (IQR)
The interquartile range (IQR) of a data set is the difference between the third quartile (Q3) and the first quartile (Q1):
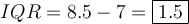
Standard Deviations
To calculate both the sample standard deviation and the population standard deviation, we must first calculate the sum of the square of each data value less the mean.
As there are only 3 different data values, we can calculate the square of each data value less the mean as follows:
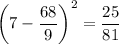
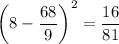
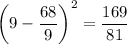
There are six 7s, one 8 and two 9s in the data set, so the sum of the square of each data value less the mean is:
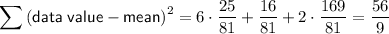
The formula for the sample standard deviation is:
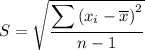
where
 is the mean, and n is the number of data values.
is the mean, and n is the number of data values.
Therefore, the sample standard deviation of the given data set is:
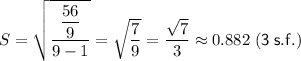
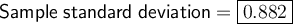
The formula for the population standard deviation is:
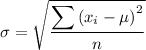
where μ is the mean, and n is the number of data values.
Therefore, the population standard deviation of the given data set is: