Answer:
A)
Mean for:
Sample Z -- 447.5
Sample Y-- 409.3
B)
Sample Y has larger deviation from the mean.
Explanation:
Z Plots Y Plots
456 395
454 390
449 391
453 402
431 395
456 405
445 432
430 438
463 420
438 425
A)
For sample Z--
The mean is calculated by:
Ratio of sum of all the data points of Z-sample to the total number of points i.e. 10.
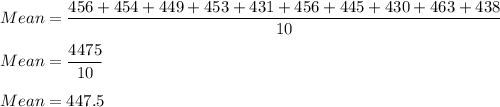
Similarly for sample Y--
The mean is calculated as follows:
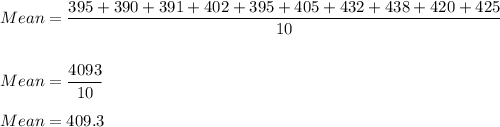
B)
As we could see that the data Y has a greater spread from the mean as compared to the sample Z.
As all the points in the sample Z are close to the mean and have less spread.
The standard deviation is most commonly used to measure the spread of the data.
Standard deviation of sample Z is: 10.651
Standard deviation of sample Y is: 16.9944
Hence Sample Y have larger deviation from the mean.