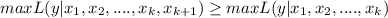Answer:
See the proof below
Explanation:
Let's assume that our random variable of interest is Y and we have a set of parameters
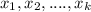 in the original network.
in the original network.
And let's assume that we add an additional parameter
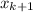 and we want to see if the likehood for
and we want to see if the likehood for
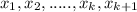
We don't know the distribution for each parameter
but we can say that the likehood function for the original set of parameters is given by:
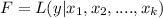
And in order to maximize this function we need to take partial derivates respect to each parameter like this:
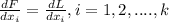
We just need to set up the last derivate equal to zero and solve for the parameters who satisfy the condition.
If we add a new parameter the new likehood function would be given by:
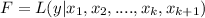
And in order to maximize this function again we need to take partial derivates respect to each parameter like this:
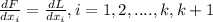
We are ssuming that we have the same parameters from 1 to k for the new likehood function. So then the likehood for the data would be unchanged and if we have more info for the likehood function we are maximizing the function since we are adding new parameters in order to estimate the function.