Answer:
a)
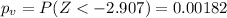
b) Since
 we can reject the null hypothesis at the significance level given. So based on this we can commit type of Error I.
we can reject the null hypothesis at the significance level given. So based on this we can commit type of Error I.
Because Type I error " is the rejection of a true null hypothesis".
c)
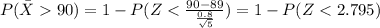
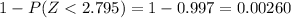
d) For this case we need a z score that accumulates 0.02 of the area on the right tail and 0.98 on the left tail and this value is z=2.054
And we can use this formula:
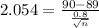
And if we solve for n we got:
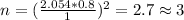
Explanation:
Previous concepts and data given
The margin of error is the range of values below and above the sample statistic in a confidence interval.
Normal distribution, is a "probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean".
We can calculate the sample mean and deviation with the following formulas:
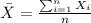
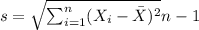
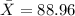 represent the sample mean
represent the sample mean
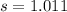 represent the sample standard deviation
represent the sample standard deviation
n=5 represent the sample selected
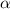 significance level
significance level
State the null and alternative hypotheses.
We need to conduct a hypothesis in order to check if the mean is less than 90, the system of hypothesis would be:
Null hypothesis:
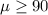
Alternative hypothesis:
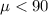
If we analyze the size for the sample is < 30 and we don't know the population deviation so is better apply a t test to compare the actual mean to the reference value, and the statistic is given by:
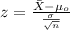 (1)
(1)
z-test: "Is used to compare group means. Is one of the most common tests and is used to determine if the mean is (higher, less or not equal) to an specified value".
Calculate the statistic
We can replace in formula (1) the info given like this:
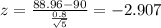
Part a
P-value
First we need to calculate the degrees of freedom given by:
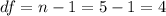
Then since is a left tailed test the p value would be:
Part b
Since
we can reject the null hypothesis at the significance level given. So based on this we can commit type of Error I.
Because Type I error " is the rejection of a true null hypothesis".
Part c
We want this probability:
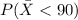
The best way to solve this problem is using the normal standard distribution and the z score given by:
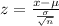
If we apply this formula to our probability we got this:
Part d
For this case we need a z score that accumulates 0.02 of the area on the right tail and 0.98 on the left tail and this value is z=2.054
And we can use this formula:
And if we solve for n we got: