Answer:
a) The 99% confidence interval would be given (0.204;0.296).
b) We have 99% of confidence that the true population proportion of all seafood sold in the country that is mislabeled or misidentified is between (0.204;0.296).
c) No that's not true. Because the necessary assumptions and conditions for the confidence interval for the proportion are satisifed, so then we can use inferential statistics to interpret the interval to the population of interest.
Explanation:
Part a
Data given and notation
n=580 represent the random sample taken
X represent the seafood sold in the country that is mislabeled or misidentified by the people
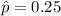 estimated proportion of seafood sold in the country that is mislabeled or misidentified by the people
estimated proportion of seafood sold in the country that is mislabeled or misidentified by the people
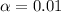 represent the significance level (no given, but is assumed)
represent the significance level (no given, but is assumed)
p= population proportion of seafood sold in the country that is mislabeled or misidentified by the people
A confidence interval is "a range of values that’s likely to include a population value with a certain degree of confidence. It is often expressed a % whereby a population means lies between an upper and lower interval".
The margin of error is the range of values below and above the sample statistic in a confidence interval.
Normal distribution, is a "probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean".
The population proportion have the following distribution
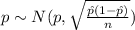
The confidence interval would be given by this formula
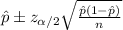
For the 99% confidence interval the value of
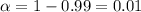 and
and
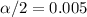 , with that value we can find the quantile required for the interval in the normal standard distribution.
, with that value we can find the quantile required for the interval in the normal standard distribution.
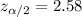
And replacing into the confidence interval formula we got:
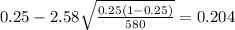
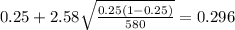
And the 99% confidence interval would be given (0.204;0.296).
Part b
We have 99% of confidence that the true population proportion of all seafood sold in the country that is mislabeled or misidentified is between (0.204;0.296).
Part c
A government spokesperson claimed that the sample size was too small, relative to the billions of pieces of seafood sold each year, to generalize. Is this criticism valid?
No that's not true. Because the necessary assumptions and conditions for the confidence interval for the proportion are satisifed, so then we can use inferential statistics to interpret the interval to the population of interest.