Answer:
Explanation:
Hello!
You have two populations "boys" and "girls" from each population a sample of 30 students is taken (n₁=n₂=30) and they resolved a standard writing test. After the test the categorized variable X: "grade obtained in a writing test" (CAT: Outstanding, Good, Passing and Failing" was registered.
The objective of the test is to determine if the variable has similar distribution across the different populations.
The statistic to use is:
χ²= ∑
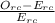 ~ χ²
~ χ²
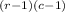
Where
r: number of populations
c: number of categories defined for the variable
In this case
χ²
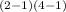 ⇒ χ²
⇒ χ²

The probability of commiting a Type I error is for every hypothesis test, regarding the statistic or distribution applied, equal to the level of significance. Always.
I hope it helps!