Answer with explanation:
Mean of a data set is defined as sum of all the observation divided by total number of observation.
For, example
Consider the Data set,the cost of five pens,={3,5,8,10,14}
Mean
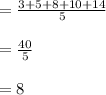
Now, Two pens having cost $ 47 and $ 53 is included in the Data set
New data set of Seven pens,={3,5,8,10,14,47,53}
Mean
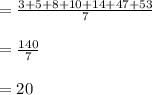
So, you can see there is variation or Difference between two means.
We can conclude from above two results ,that mean is affected by outlier.