Answer:
a)
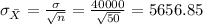
b) Since the distribution for X is normal then we know that the distribution for the sample mean
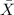 is given by:
is given by:
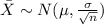
c)
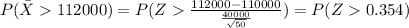
And we can use the complement rule and we got:
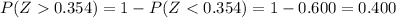
d)
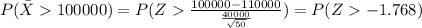
And we can use the complement rule and we got:
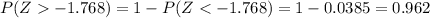
e)
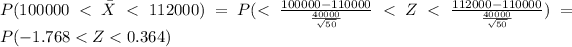
And we can use the complement rule and we got:
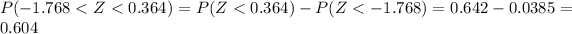
Explanation:
a. If we select a random sample of 50 households, what is the standard error of the mean?
Previous concepts
Normal distribution, is a "probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean".
The Z-score is "a numerical measurement used in statistics of a value's relationship to the mean (average) of a group of values, measured in terms of standard deviations from the mean".
Let X the random variable that represent the amount of life insurance of a population, and for this case we know the distribution for X is given by:
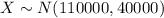
Where
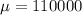 and
and
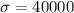
If we select a sample size of n =35 the standard error is given by:
b. What is the expected shape of the distribution of the sample mean?
Since the distribution for X is normal then we know that the distribution for the sample mean
is given by:
c. What is the likelihood of selecting a sample with a mean of at least $112,000?
For this case we want this probability:
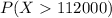
And we can use the z score given by:
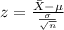
And replacing we got:
And we can use the complement rule and we got:
d. What is the likelihood of selecting a sample with a mean of more than $100,000?
For this case we want this probability:
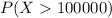
And we can use the z score given by:
And replacing we got:
And we can use the complement rule and we got:
e. Find the likelihood of selecting a sample with a mean of more than $100,000 but less than $112,000
For this case we want this probability:
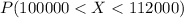
And we can use the z score given by:
And replacing we got:
And we can use the complement rule and we got: