Answer:
The data for the control group has a first common difference, therefore the data is being generated by a linear function
The data for the original group has a second common difference, therefore the data is being generated by a quadratic function
The data for the Improved group has a common ratio, therefore the data is being generated by an exponential function
Step-by-step explanation:
Given the table in the attached image.
The data for the control group has a common difference, that is the difference between consecutive values are the same.

Since the values have a common difference then it is a linear function.
The original formula has a second common difference, therefore the data is being generated by a quadratic function.
The improved formula has a common ratio;
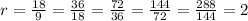
Therefore, the data is being generated by an exponential function.